ClickHouse官方文档阅读(DBT)
ClickHouse官方文档阅读(DBT)
Requirement
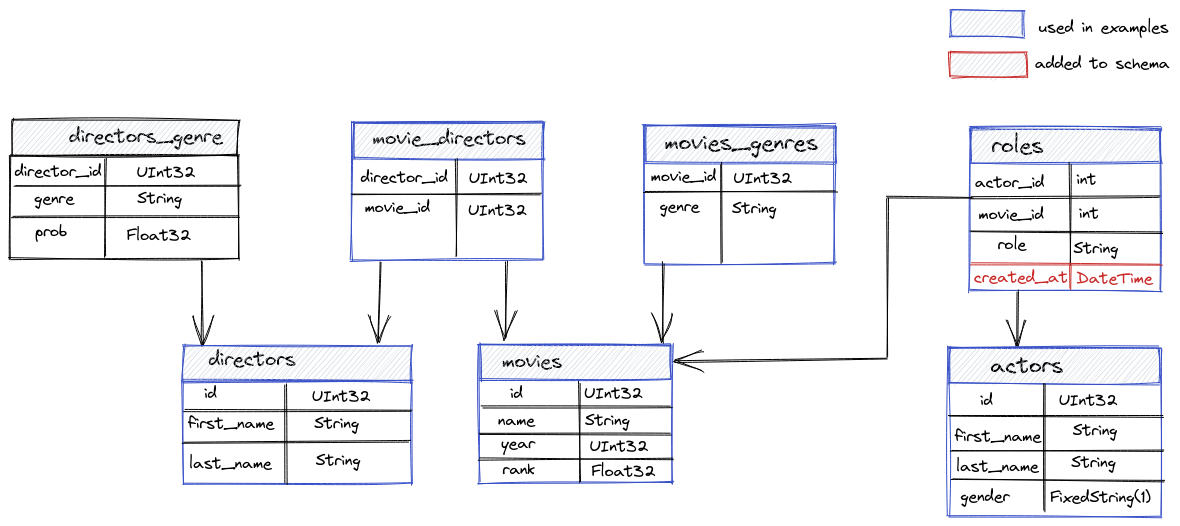
数据关系图
下载数据到本地
- 使用
wget下载数据到本地
1
2
3
4
5
6
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_actors.tsv.gz
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_directors.tsv.gz
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies_genres.tsv.gz
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies_directors.tsv.gz
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies.tsv.gz
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_roles.tsv.gz
- 解压数据,准备下一步导入 clickhouse
导入数据
- 从 tsv 导入数据
1
2
3
4
5
6
clickhouse client -q "INSERT INTO imdb.actors FORMAT TabSeparatedWithNames" < imdb_ijs_actors.tsv
clickhouse client -q "INSERT INTO imdb.directors FORMAT TabSeparatedWithNames" < imdb_ijs_directors.tsv
clickhouse client -q "INSERT INTO imdb.genres FORMAT TabSeparatedWithNames" < imdb_ijs_movies_genres.tsv
clickhouse client -q "INSERT INTO imdb.movie_directors FORMAT TabSeparatedWithNames" < imdb_ijs_movies_directors.tsv
clickhouse client -q "INSERT INTO imdb.movies FORMAT TabSeparatedWithNames" < imdb_ijs_movies.tsv
clickhouse client -q "INSERT INTO imdb.roles(actor_id, movie_id, role) FORMAT TabSeparatedWithNames SELECT actor_id, movie_id, role FROM" < imdb_ijs_roles.tsv
进行查询
- 查询参演电影数最多的五名演员的统计情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
SELECT
id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as unique_genres,
uniqExact(director_name) as uniq_directors,
max(created_at) as updated_at
FROM
(
SELECT
imdb.actors.id as id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) as actor_name,
imdb.movies.id as movie_id,
imdb.movies.rank as rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) as director_name,
created_at
FROM
imdb.actors
JOIN imdb.roles ON
imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON
imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON
imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON
imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON
imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY
id
ORDER BY
num_movies DESC
LIMIT 5;
View Materialization
Table Materialization
Incremental Materialization
- 往数据库里写入新数据
1
2
3
4
5
6
7
8
INSERT INTO imdb.actors VALUES (845466, 'Clicky', 'McClickHouse', 'M');
-- 新增一个 actor
INSERT INTO imdb.roles
SELECT now() as created_at, 845466 as actor_id, id as movie_id, 'Himself' as role
FROM imdb.movies
LIMIT 910 OFFSET 10000;
-- Let's have Clicky star in 910 random movies
- 执行分析,通过查询系统日志,对 DBT 的执行过程进行分析
1
2
3
4
5
SELECT event_time, query FROM system.query_log WHERE type='QueryStart' AND query LIKE '%dbt%'
AND event_time > subtractMinutes(now(), 15) ORDER BY event_time LIMIT 100;
-- 查看 DBT 执行的操作过程
DROP table system.query_log
-- 删除查询日志(debug 用)
Internals
流程分析
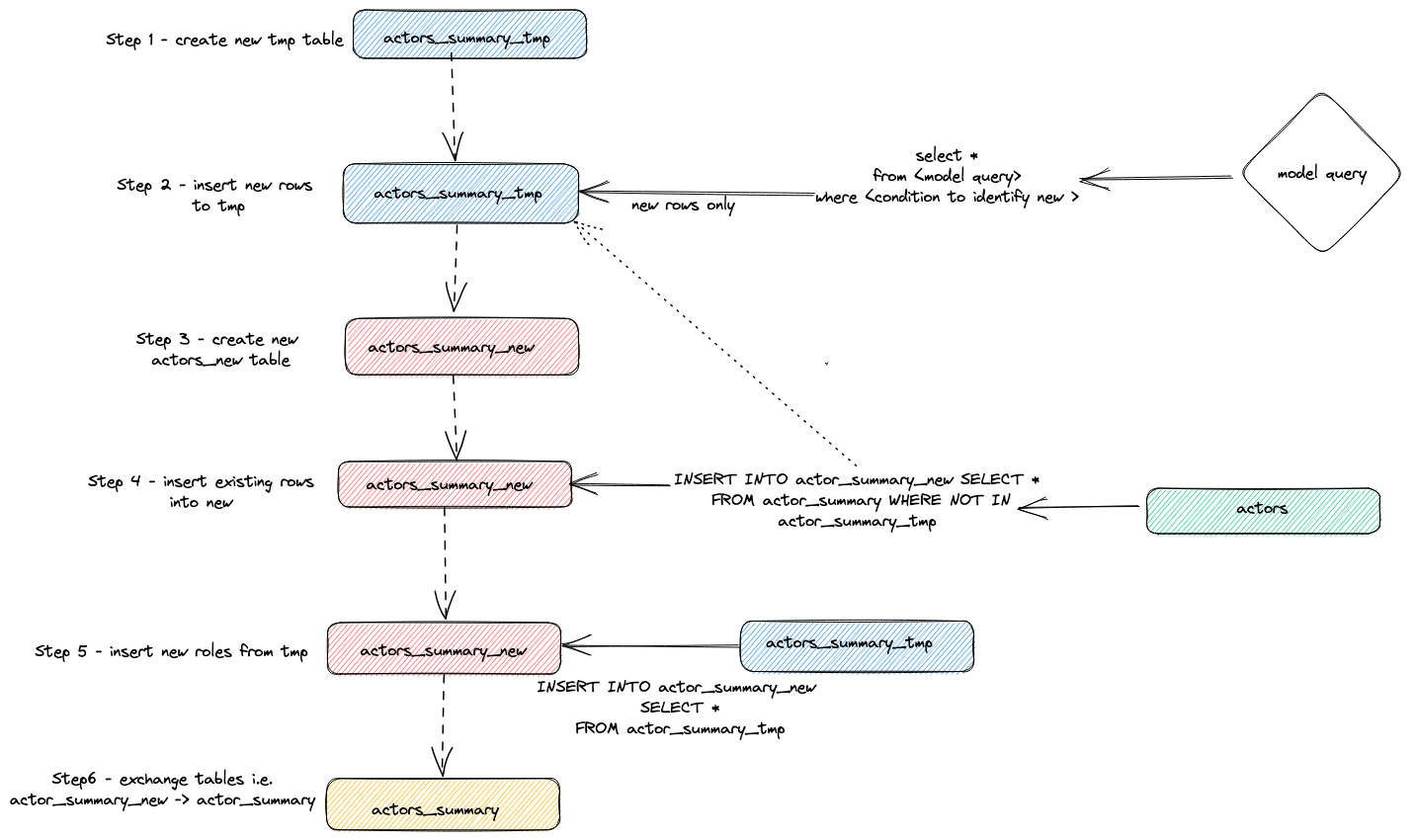
- The plugin creates a temporary table
actor_sumary__dbt_tmp. Rows that have changed are streamed into this table. - A new table,
actor_summary_newis created. The rows from the old table are, in turn, streamed from the old to new, with a check to make sure row ids do not exist in the temporary table. This effectively handles updates and duplicates. - The results from the temporary table are streamed into the new
actor_summarytable: - Finally, the new table is exchanged atomically with the old version via an
EXCHANGE TABLESstatement. The old and temporary tables are in turn dropped.
Append Strategy (inserts-only mode)
To overcome the limitations of large datasets in incremental models, the plugin uses the dbt configuration parameter incremental_strategy. This can be set to the value append. When set, updated rows are inserted directly into the target table (a.k.a imdb_dbt.actor_summary) and no temporary table is created. Note: Append only mode requires your data to be immutable or for duplicates to be acceptable. If you want an incremental table model that supports altered rows don’t use this mode!
⚠️ 好处是减少了大量的数据写入操作,但如果要进行行修改,不要用此模式
配置策略
1
2
3
4
5
6
7
8
9
10
11
12
13
14
-- config(materialized='view')
-- table 视图策略
-- config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='table')
-- table 策略
-- config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id')
-- 增量策略一:merge
-- config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id', incremental_strategy='append')
-- 增量策略二:append
-- config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id', incremental_strategy='delete+insert')
-- 增量策略三:delete + insert
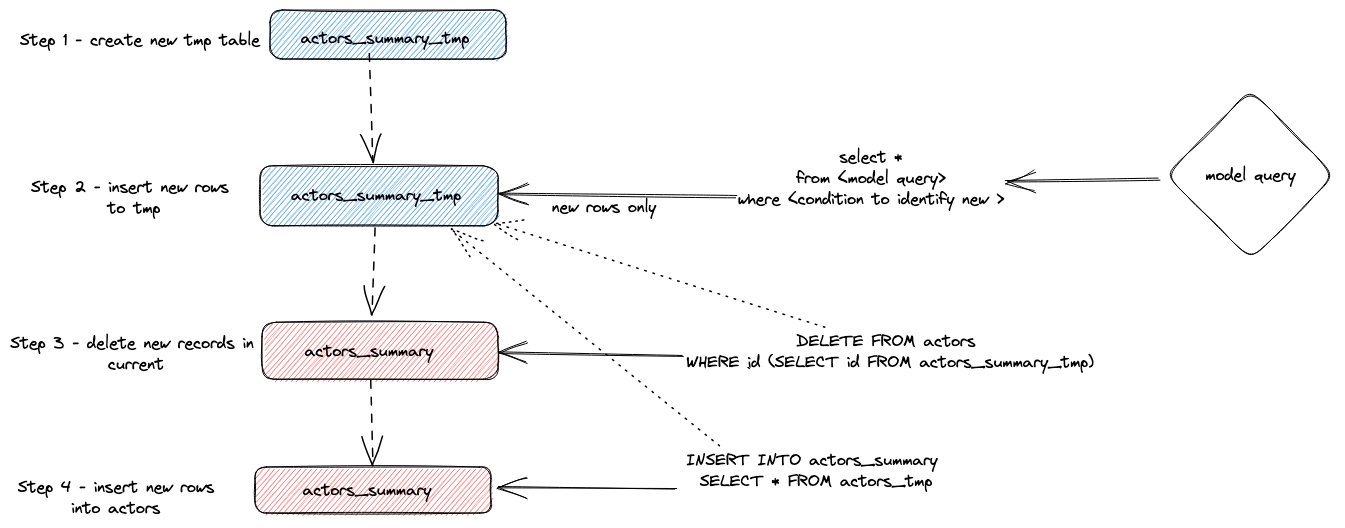
Delete+Insert mode (Experimental)
流程分析
- The plugin creates a temporary table
actor_sumary__dbt_tmp. Rows that have changed are streamed into this table. - A
DELETEis issued against the currentactor_summarytable. Rows are deleted by id fromactor_sumary__dbt_tmp - The rows from
actor_sumary__dbt_tmpare inserted intoactor_summaryusing anINSERT INTO actor_summary SELECT * FROM actor_sumary__dbt_tmp.
Snapshots
- 特点
- 行列级别的数据变化记录,每次执行完 update 操作后,再执行
dbt snapshot,就会产生相关的 snapshots 记录
- 行列级别的数据变化记录,每次执行完 update 操作后,再执行
- 文档
Seeds
Limitations
This post is licensed under CC BY 4.0 by the author.